
這幾天因為考慮安裝 Hermes Agent,而我也想保留 OpenClaw,但目前我買的 MiniMax 方案只支援給一個機器人使用,所以我就開始考慮要裝一個本地模型來測試看看效能如何,不過,現在太多模型讓自己很眼花撩亂,加上許多使用者似乎對於模型都評價不一,所以我最後決定自己裝幾個來測試看看。
因為是新手嘗試使用本地模型,加上2月當時懵懵懂懂的使用Ollama安裝之後,卻總是得到「龜速回覆」卻不知道問題在哪,查了半天才發現在 Mac 上要使用 Apple 的 MLX 框架安裝才可以利用 Apple Silicon(M1/M2/M3/M4)的統一記憶體架構實現高效推理。
Ollama其實三月份的改版也開始支援MLX模型了,不過前陣子看到許多人在說新的 Gemma 4,但我在LM Studio才找到mlx的版本,所以最後決定安裝LM Studio來測試不同的模型:
一、安裝 LM Studio
先到LM Studio官網:https://lmstudio.ai
點選下載按鈕:
之後點選下載後的檔案再拖拉圖示到Applications的資料夾中:

之後就可以在電腦的應用程式中找到 LM Studio 的應用程式了,然後執行它:

第一次執行時,電腦會跳出提示,請點選「打開」:
然後就會看到 LM Sudio的第一次設定畫面,請點選下方[Get Started]:
點選開始之後,LM Studio就先推薦安裝gemma-4-e4b,如果想嘗試的人可以直接點選下載,但我一開始先選擇 [Skip for now],因為我想自己查詢看看不同的模型再做決定:
之後就會看到進階設定的畫面了,畫面上這兩個選項分別是:
- Turn on Developer Mode:這個是詢問你要不要開起[開發模式],如果之後需要跟自己的OpenClaw或是Hermes Agent就要打開,這樣後續才可以設定本地伺服器和機器人做連接,如果只是想先測試模型也可以先不開,等到需要的時候再開啟就好。
- Start local LLM service on login:這是問你要不要開機時就一起啟動本地模型,跟上面一樣,如果你有持續使用本地模型的需求,也可以開啟。
之後就會跳進[跟模型聊天]的畫面了(但此時還沒有安裝任何本地模型):
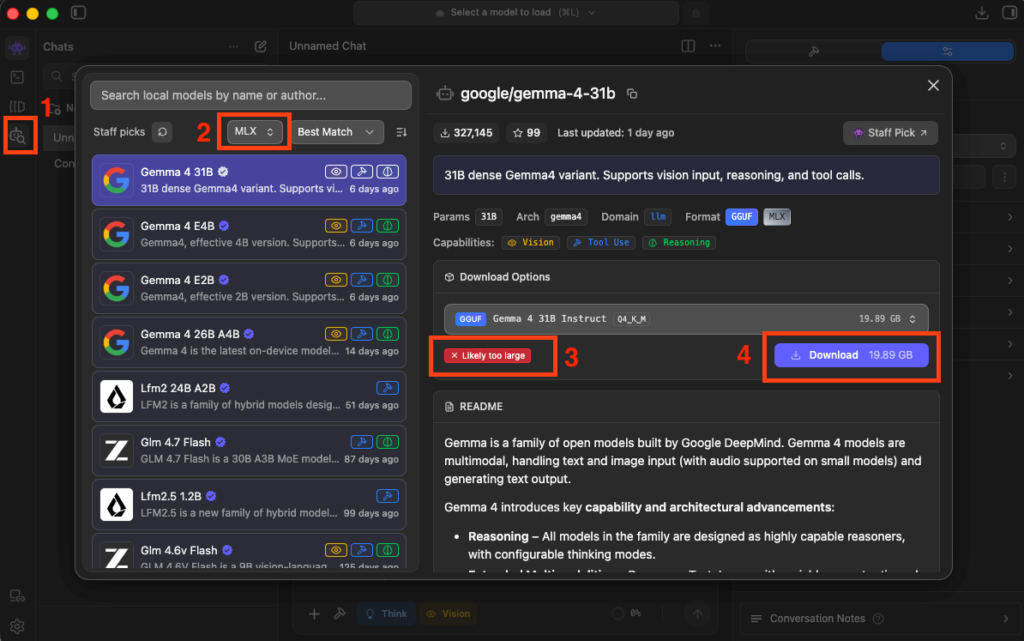
二、下載模型
剛開始使用,當然要先下載模型,所以先簡單了解一下畫面上的功能:
- 左方選單要先點選[model search]的圖示
- 因為我是Mac電腦,所以當然會希望使用 MLX 模型來實現高效模型,所以類型會選擇[MLX]
- 點選模型後,其實介面上會先以你目前的環境給出建議,如果顯示像下圖的[Likely too large]就表示目前這台電腦跑不動這個模型,所以如果一開始不太懂自己電腦適合哪些模型倒是可以參考一下
- 等選定自己想要測試的模型之後,就可以按下Download按鈕
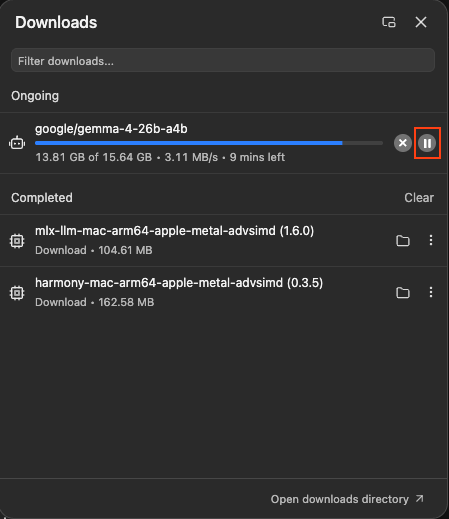
LM Studio有時下載會突然卡住,雖然我下載了5個模型只遇到一次這樣的狀況,不過如果不幸發生這樣的情況也不用慌張,就再點選一次剛剛的[download]按鈕,就會跳出以下視窗,之後按下暫停等個10秒左右再啟動,卡住的狀況就解決了:
等到模型下載完成,原先的[Download]按鈕就會變成[Use in New Chat],就可以直接測試使用這個模型對話:
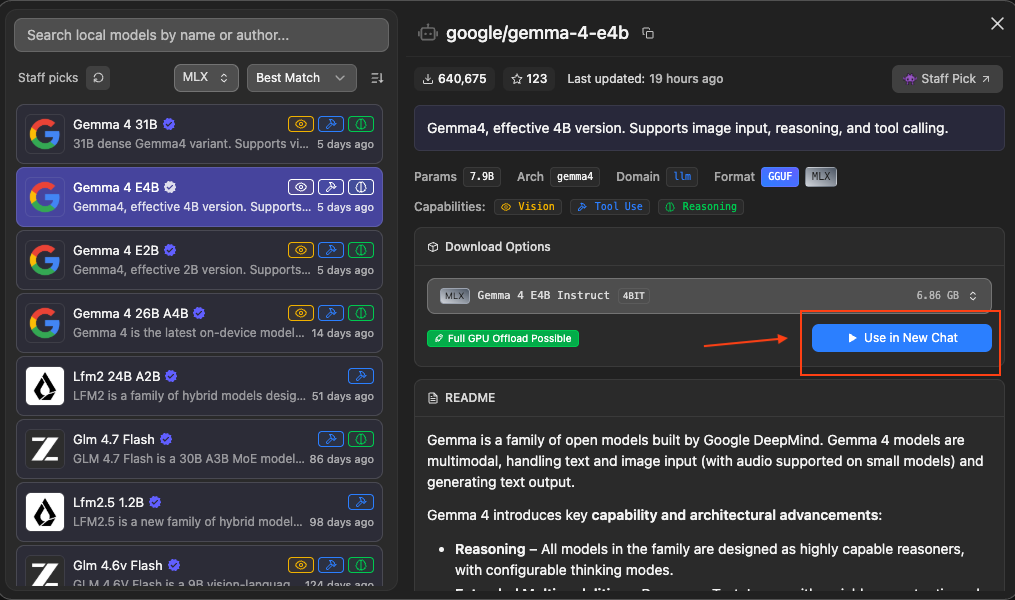
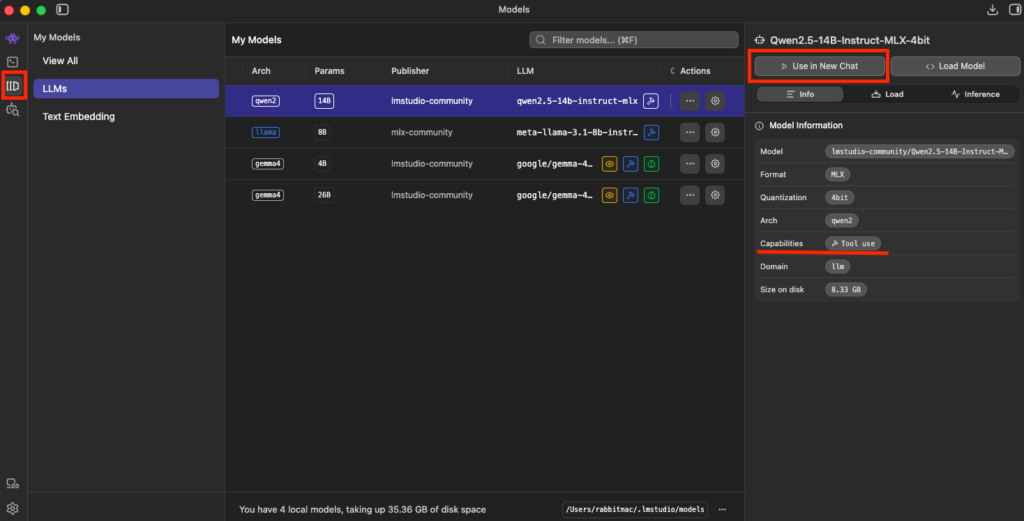
如果想一次先下載多個模型再測試,也可以直接繼續搜尋模型進行下載,之後再用左側按鈕選擇[My models]的圖示,就可以看到自己目前有下載的本地模型,然後再由這個畫面切換模型進行聊天測試:
三、簡單的模型測試
我這次選擇了3個本地模型測試,分別是:
- qwen3.5-9b-mlx
- glm-4.6v-flash
- gemma-4-e4b
主要想看看這三個的[文字風格]、[圖片辨識]、[回應時間]和[我的記憶體使用量](畢竟記憶體夠不夠用還是很現實的問題…)
所以我用同一張圖片請三個模型各自跟我描述圖片,也用同一個文字問題詢問三個模型,測試之後的數據和我個人的感覺如下:
| 模型名稱 | qwen3.5-9b-mlx | glm-4.6v-flash | gemma-4-e4b |
| 圖片辨識 模型思考時間 ( 秒數 ) | 40.31 | 20.45⭐ | 23.12 |
| 圖片辨識 模型回應時間 ( 秒數 ) | 2.10 | 3.02 | 1.31⭐ |
| 圖片辨識 Tok/Sec | 20.88 | 18.71 | 21.65 |
| 圖片辨識 Tokens | 1431 | 740 | 990 |
| 文字問題 模型思考時間 ( 秒數 ) | 60 | 22.03 | 21.68⭐ |
| 文字問題 模型回應時間 ( 秒數 ) | 4.13 | 6.34 | 1.47⭐ |
| 文字問題 Tok/Sec | 20.7 | 18.54 | 21.65 |
| 文字問題 Tokens | 2125 | 522 | 1018 |
| RAM 使用 | 6.04 GB⭐ | 7.23 GB | 6.54GB |
- 針對[圖片辨識]:其實我個人比較喜歡 GLM 的回答,因為我放進去讓模型辨識的圖片-其實是我用文生圖的模型做出的圖片,qwen和gemma其實陳述的內容差不多,但 GLM 讓我很訝異 – 它幾乎說出了我當初生成圖片時所用的幾個重要提示詞。
- 針對[文字回應]:GLM的回應感覺是三個裡面最簡單的,Gemma在回應速度上的表現最亮眼,不過測試很多次之後,我發現Gemma有時會出現我看不懂的亂碼文字,這我目前還不知道是為什麼…
- RAM的使用量:qwen的RAM使用量上是最低的。因為我目前是 24GB 的記憶體,加上基本使用大約就佔 7-8GB 左右了,如果之後還要執行其他應用程式或瀏覽器開啟網頁…等都會需要占用記憶體,因此這個使用量對我來說也是一個參考的重要標準…
目前這些都是簡單的測試,也推薦給想小試本地模型的人用這樣的方式就可以大略的體驗一下在自己的Mac 上跑本地模型 – 找到適合自己電腦和個人較欣賞的模型回應風格,之後 就可以考慮是否能用在自己的OpenClaw或Hermes Agent上,這樣就可以省掉一筆token的費用囉!